Fraud Detection Platform
Machine learning in a Jupyter Notebook is easy. Deploying it to process sub-second predictions reliably in production is a completely different engineering challenge.
Sentinel is an end-to-end, production-grade MLOps platform I designed to handle real-time credit card fraud detection. Rather than just training a model, this project focuses on the surrounding infrastructure: automated feature engineering, continuous model training, and low-latency serving. It is built to demonstrate how AI acts as a scalable business engine when backed by robust operations.
🔗 View the full source code and documentation on GitHub
The Architecture: Moving Beyond the Notebook Link to heading
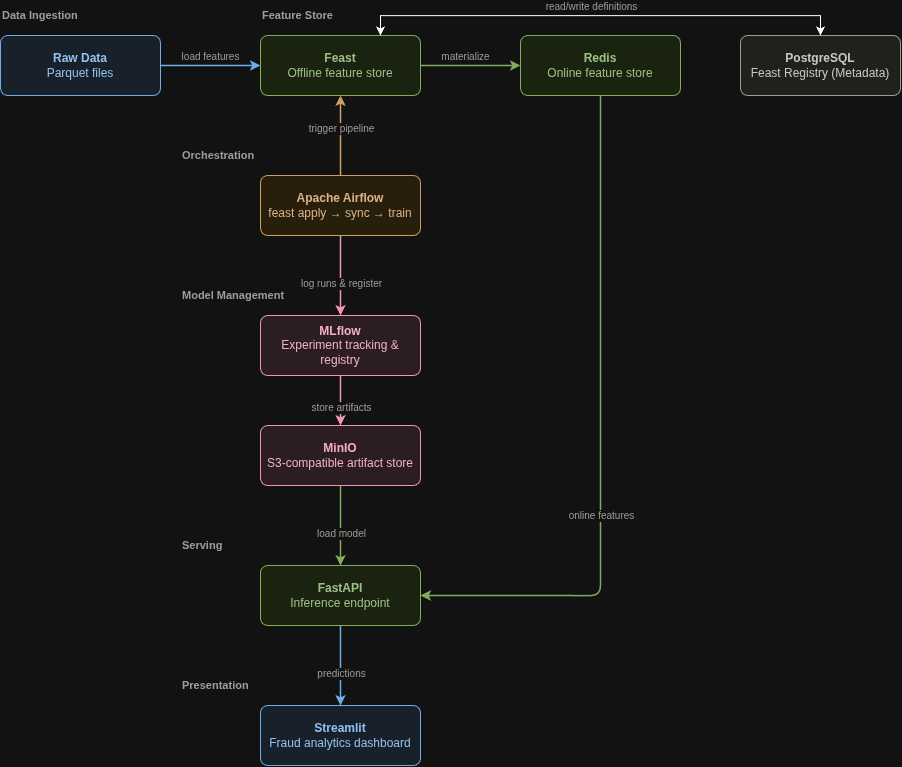
To handle the lifecycle of an ML model in production, Sentinel relies on a microservices architecture orchestrated via Docker Compose. The system is broken down into distinct layers to handle data ingestion, feature storage, orchestration, and real-time serving.
The Core Tech Stack:
- Workflow Orchestration: Apache Airflow
- Feature Store: Feast (with PostgreSQL for the registry and Redis for the online store)
- Model Management & Tracking: MLflow & MinIO (S3-compatible storage)
- Real-Time Serving: FastAPI
- Infrastructure: Docker & Docker Compose
Key Engineering Features Link to heading
1. Automated ML Pipelines Link to heading
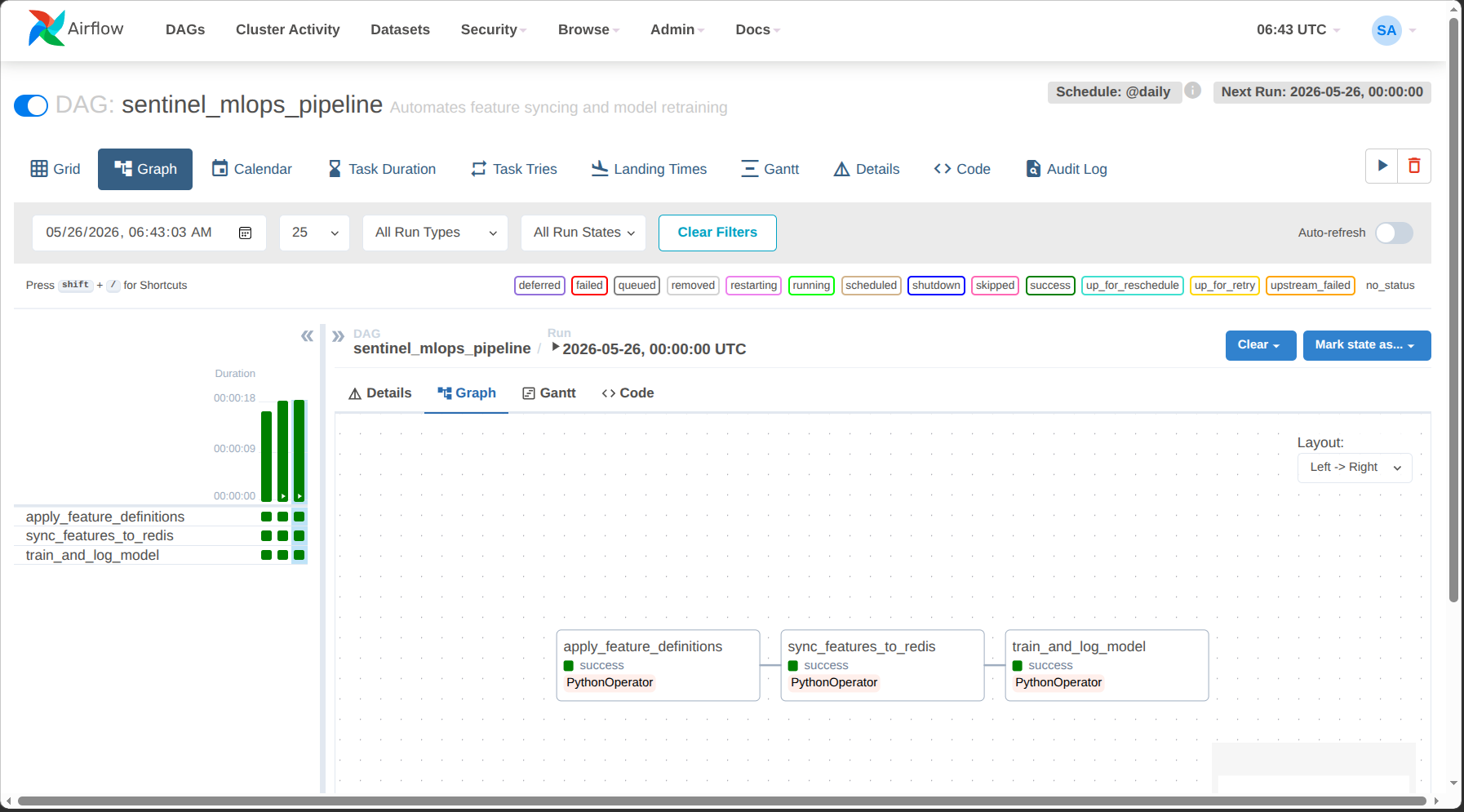
Sentinel doesn’t rely on manual triggers. An Apache Airflow DAG runs daily, automating a three-stage pipeline:
- Feature Definition: Applies Feast feature views to the PostgreSQL registry.
- Smart Materialization: Handles both full data materialization for initial setups and incremental updates for subsequent runs directly into Redis.
- Model Training: Fetches historical feature vectors from Feast’s offline Parquet store, trains a Random Forest Classifier, logs all metrics to MLflow, and saves the artifacts to MinIO.
2. Real-Time Feature Serving Link to heading
Fraud detection requires extreme low latency. When a transaction hits the FastAPI endpoint, it cannot wait for complex database joins to fetch user history. Sentinel uses Feast to solve this. The offline store (Parquet) handles bulk training data, while the online store (Redis) serves pre-computed features in under 10 milliseconds for the active model to run its inference.
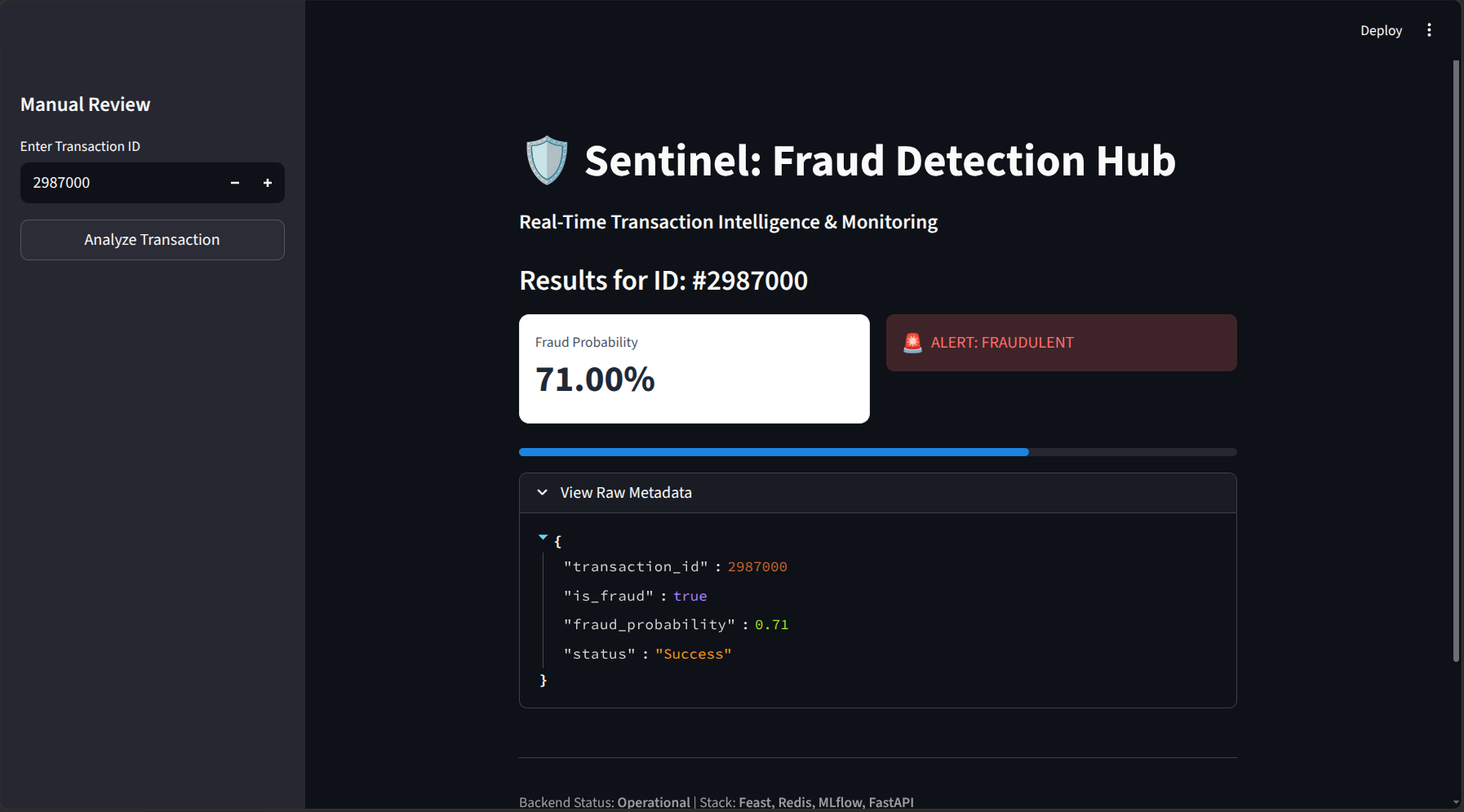
3. Decoupled Model Serving Link to heading
The FastAPI prediction endpoint acts as a lightweight wrapper. On startup, it dynamically loads the latest production-approved model from MinIO and connects to the Feast online store.
Example API Response:
{
"transaction_id": 2987000,
"is_fraud": true,
"fraud_probability": 0.71,
"status": "Success"
}
Current Status and the Roadmap Ahead Link to heading
Building an MLOps platform is an iterative process. Currently, the infrastructure is solid 8 containers communicating seamlessly across an orchestrated network, successfully processing a 50,000+ transaction dataset.
While the baseline accuracy sits at 97.7%, the recall is currently 35%. The infrastructure is now ready to support the next phases of development:
- Model Tuning: Implementing hyperparameter optimization and advanced feature engineering to drastically improve recall.
- System Monitoring: Integrating Prometheus and Grafana to track data drift and model degradation over time.
- Advanced Deployment: Setting up A/B testing frameworks for shadow deployments and eventually migrating the containerized stack to the cloud.
Sentinel is a living project that serves as a sandbox for scaling AI operations. If you are interested in the granular setup instructions or want to run the platform locally, check out the GitHub repository.