Generative AI at the moment Link to heading
Generative AI, particularly propagated by large language models (LLMs), is a rapidly advancing field with numerous exciting developments. LLMs, like GPT-4, exhibit remarkable proficiency in generating coherent and contextually relevant text. Capable of producing grammatically correct and semantically meaningful content, these models have found applications in diverse domains, such as generating articles, stories, chatbot responses, and even entire books. The key strength of LLMs lies in their capacity to learn complex language patterns from vast datasets, enabling them to generate text with a level of complexity and nuance that manual programming would struggle to achieve.
The effectiveness of LLMs in generative AI is further amplified by their adaptability. These models can be fine-tuned for specific tasks, allowing customization of text generation for particular styles, tones, or contexts. This flexibility renders LLMs invaluable for applications ranging from content creation to the development of chatbots and virtual assistants. However, harnessing the full potential of LLMs poses challenges. Ensuring that the generated text is not only coherent but also relevant and useful requires careful tuning and evaluation of model parameters. Additionally, addressing concerns about bias or offensive content is crucial, necessitating vigilant monitoring and ethical considerations throughout the development process.
Despite these challenges, the trajectory of LLMs in generative AI promises continued innovation and impact. As technology advances, we can anticipate a increase in the use of LLM applications across diverse domains, shaping the future of content creation, conversational interfaces, and beyond.
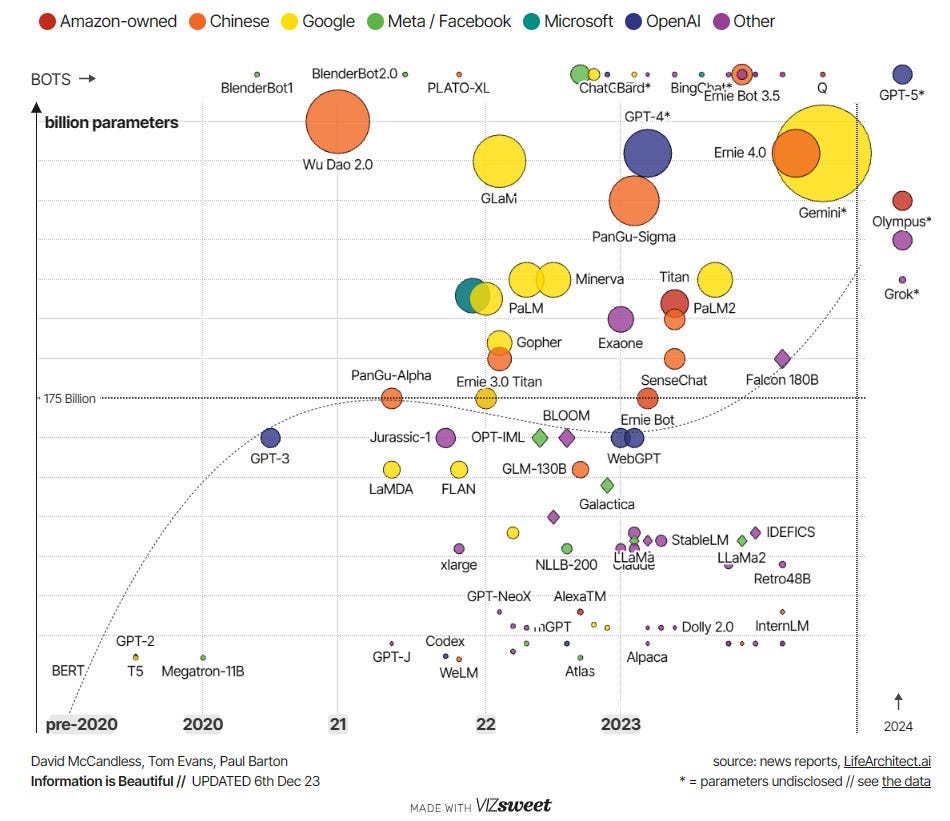
Below is an image of several different LLMs. Here is the interactive view.
Prompt Engineering
I honestly never thought that a name like that could ever be possible. Anyway, prompt engineering refers to the intentional crafting of prompts or input queries to achieve desired outputs from LLMs. Effective prompt engineering is crucial for obtaining accurate and relevant responses from these models. I didn’t believe at first until I tried. Here is a guide that could be really helpful. Also, here is a collection of awesome ChatGPT prompts.
Langchain
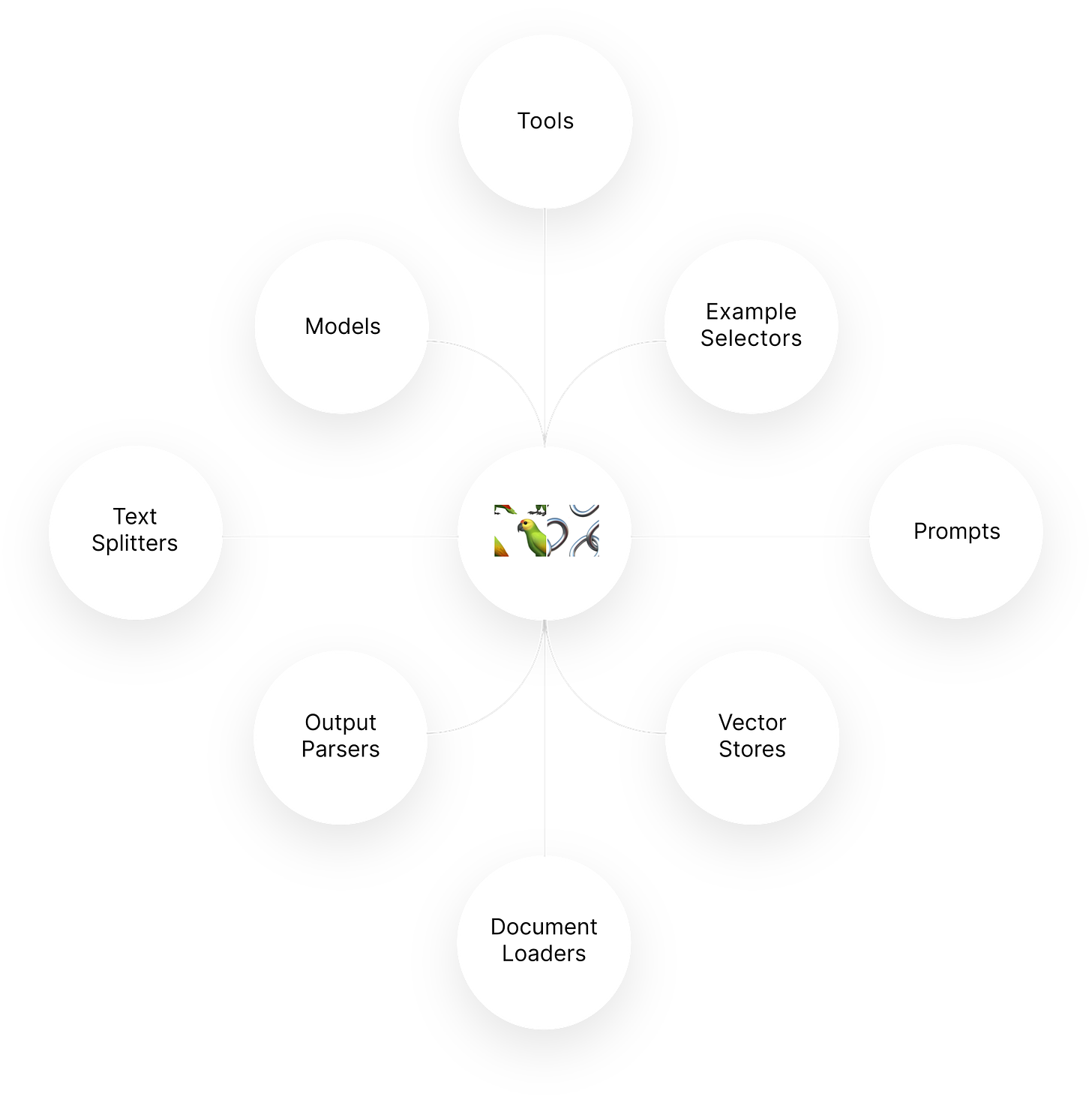
Basically, Langchain is a project that enhances the capabilities of language models by providing a set of tools and best practices for developing applications with LLMs. It makes developers like us leverage LLMs in various ways, like building chatbots, creating content, generating summaries, and even RAG (Retrieval Augmented Generation; more about this later). Not only is the project a good one, but it also has nice documentation.
Token and Tokenization
In computer science and natural language processing, a token is the smallest unit of meaning in a piece of text. It can be as short as one character or as long as one word. Tokens serve as the building blocks for more advanced language processing tasks, such as parsing, part-of-speech tagging, and sentiment analysis.
Tokenization is the process of breaking down a piece of text into its constituent tokens. This process is often the first step in many NLP pipelines, as it allows us to represent the text in a way that can be easily processed by machine learning algorithms.
There are several different types of tokens that we might encounter in NLP, including:
Words: These are the most common type of token, and they represent individual words in the text. For example, in the sentence “The quick brown fox jumps over the lazy dog,” we have five words: “the,” “quick,” “brown, “fox,” “jumps”, “over”, “the”, “lazy”, “dog.”
Punctuation: Tokens can also represent punctuation marks, such as periods, commas, and question marks. In the sentence “What’s the meaning of life?” we have a question mark token at the end of the sentence, which can be represented by a token.
Special characters: Tokens can also represent special characters, such as @, #, and $. For example, in the sentence “My email address is myemail@example.com,” we have a special character token for the “@” symbol.
Digits: Tokens can also represent digits, such as 0, 1, 2, etc. For example, in the sentence “The answer is 42,” we have a digit token for the number 42.
Emojis: Tokens can also represent emojis, which are used to convey emotions or ideas in text. For example, in the sentence “I love ❤️ pizza 🍕,” we have two emoji tokens, one representing a pizza and the other representing a heart.
Tokenization can be done in different ways, depending on the specific use case and the desired level of granularity. Some common methods of tokenization include:
Word-level tokenization: This involves breaking down the text into individual words, separated by spaces or other special characters. For example, the sentence “The quick brown fox jumps over the lazy dog” would be tokenized as [“The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”].
Character-level tokenization: This involves breaking down the text into individual characters rather than words. For example, the sentence “The quick brown fox jumps over the lazy dog” would be tokenized as [“T”, “h”, “e”, “ “, “q”, “u”, “i”, “c”, “k”, “ “, “b”, “r”, “o”, “w”, “n”, “f”, “o”, “x”, “j”, “u”, “m”, “p”, “s”, “o”, “v”, “e”, “r”, “t”, “h”, “e”, “l”, “a”, “z”, “y”, “d”, “o”, “g”].
Subword-level tokenization: This involves breaking down words into subworlds, which are contiguous sequences of characters within a word. For example, the word “quick” could be tokenized as [“qui”,” ck”].
Vector Databases
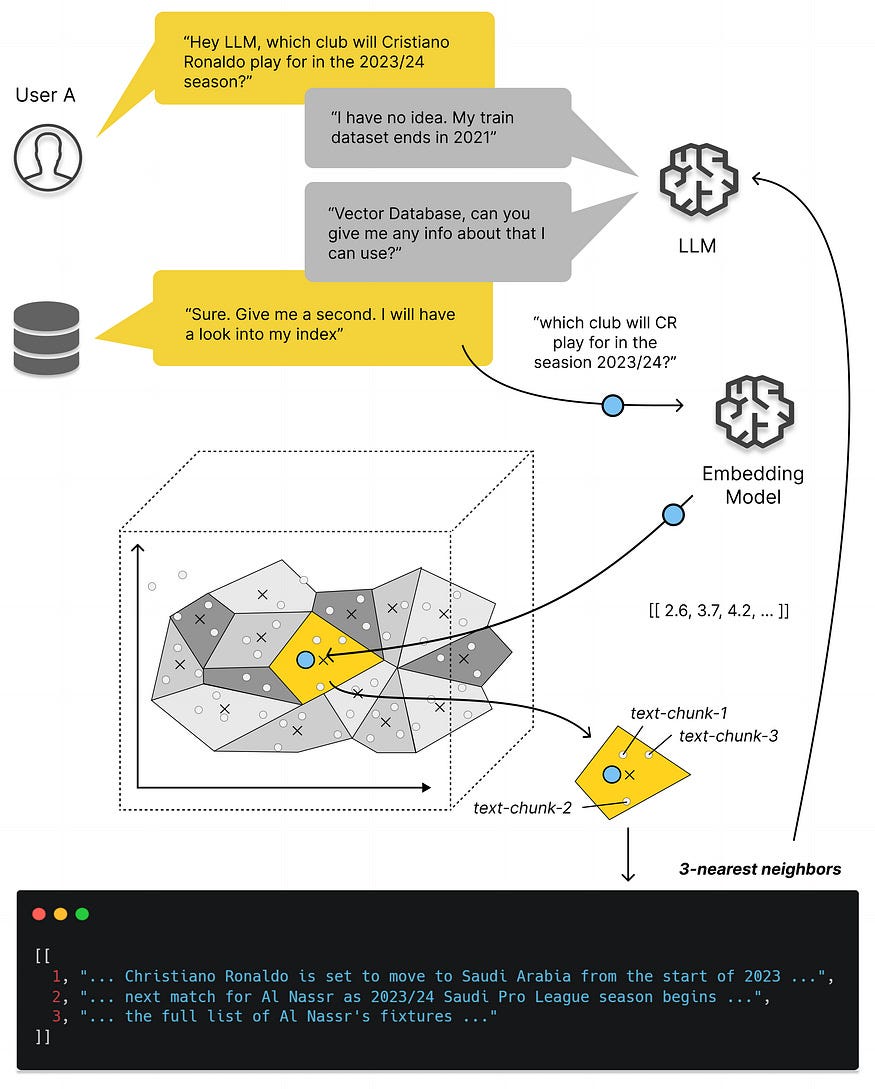
Following the picture above, the LLM is asked a question by the user, and then it cannot give the answer because of its training cutoff, so it proceeds to the vector database. The vector database is designed to store, manage, and index massive quantities of high-dimensional vector data efficiently. Unlike traditional databases with rows and columns, data points in a vector database are represented by vectors with a fixed number of dimensions, clustered based on similarity. This design enables low-latency queries, making them ideal for AI-driven applications. The use of vector databases in the real world is increasing because of the growth of unstructured data, which comprises images, videos, audio clips, and media posts. Typically, storing this in a traditional relational database is labor-intensive and inefficient. Traditional relational databases are used for storing structured or semi-structured data in specific formats, while vector databases are best suited for unstructured data through their vector embeddings.
Vector and Vector Embeddings
In the realm of mathematics, a vector is essentially an ordered set of numbers, and it has both magnitude and direction. In a more precise manner, vectors exist in a vector space, obeying certain rules like vector addition and scalar multiplication. Each number in a vector represents a coordinate in a specific dimension, and together they form an arrow in that multidimensional space. So, when you hear about a 3D vector, imagine a mathematical arrow floating in a three-dimensional universe, with its coordinates determining its position.
Similarly, in AI, vectors are an array of numbers that can represent complex objects like words, images, videos, and audio. Converting text to vectors can be achieved by using natural language processing techniques like Bag of Words (BOW), Term Frequency-Inverse Document Frequency (TF-IDF), Word Embeddings (Word2Vec, GloVe), etc. The number of vectors continues to grow, so there is a need for a vector database. Vectors that are represented in large continuous multidimensional spaces are known as embeddings, which are generated by embedding models (for example, OpenAI embeddings). Vector databases then store and index the output of the embedding model.
When we talk about embedding words or phrases, we’re essentially converting them into vectors in a high-dimensional space. Picture this space as a hyperspace where each dimension corresponds to a unique linguistic feature. So, words with similar meanings or contextual relationships end up being close to each other in this abstract, high-dimensional cosmos.
For example, in the word embedding space, the word “king” might be close to “queen” because they share a semantic relationship, and the vector arithmetic like “king — man + woman” results in a vector close to “queen.” This isn’t magic; it’s the mathematical beauty of vector spaces!
Example of a Vector:
A vector is a mathematical object that has both magnitude and direction. In a 2-dimensional space, a vector can be represented as (x, y), where ‘x’ and ‘y’ are the components of the vector.
Example: Consider the 2D vector V = (3, 4). This vector has a magnitude of 5 (calculated as the square root of the sum of the squares of its components) and points in the direction of the positive x-axis.
Example of Vector Embedding:
Vector embeddings are a way to represent words, phrases, or even larger pieces of text as vectors in a high-dimensional space. These embeddings are used in natural language processing (NLP) tasks.
Example: Let’s say we have a simple vocabulary with three words: “cat,” “dog,” and “fish.” We can represent these words as vectors in a 3-dimensional space.
The vector embedding for “cat” might be (0.9, 0.5, 0.2).
The vector embedding for “dog” might be (0.8, 0.7, 0.1).
The vector embedding for “fish” might be (0.3, 0.6, 0.9).
In this example, the numbers in the vectors represent the position of each word in the 3-dimensional space. The idea is that words with similar meanings or contexts are represented by vectors that are close to each other in this high-dimensional space.
Vector embeddings are particularly useful in machine learning models for tasks like natural language understanding and language translation. They allow the model to capture semantic relationships between words and improve its performance on various NLP tasks.
Vector databases are used to efficiently store and query vector embeddings. These databases are designed to handle high-dimensional vectors and provide fast retrieval based on similarity searches. Here’s a simplified example:
Let’s consider a vector database for storing the vector embeddings of animals in a 3-dimensional space.
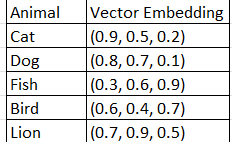
In this example, each row represents an animal along with its vector embedding in a high-dimensional space. A vector database would efficiently store these embeddings and allow for fast retrieval based on similarity searches.
Suppose you want to find animals similar to a given query vector, let’s say (0.85, 0.6, 0.15). You can perform a similarity search in the vector database to find the closest vectors to the query. In this case, it might return “cat” and “dog,” as they have similar vector embeddings.
When we’re dealing with vast sets of these high-dimensional vectors, we need specialized databases to efficiently manage and query them. Vector databases, like the superheroes of data storage, employ advanced algorithms to navigate through these vector spaces and retrieve the most relevant vectors swiftly.
They might use tree structures or fancy tricks like locality-sensitive hashing (LSH) to organize and index these vectors, ensuring that when you ask for something like “find me similar vectors,” it doesn’t have to scan the entire universe — just the neighborhood.
In essence, vector databases are like the librarians of the vector world, ensuring that the vast information encoded in these high-dimensional vectors is organized, accessible, and ready for nerdy queries.
RAG Link to heading
RAG is a technique that combines LLMs with an external knowledge base, allowing the model to add relevant information not included in the original training set to the model.
RAG architecture has two main parts:
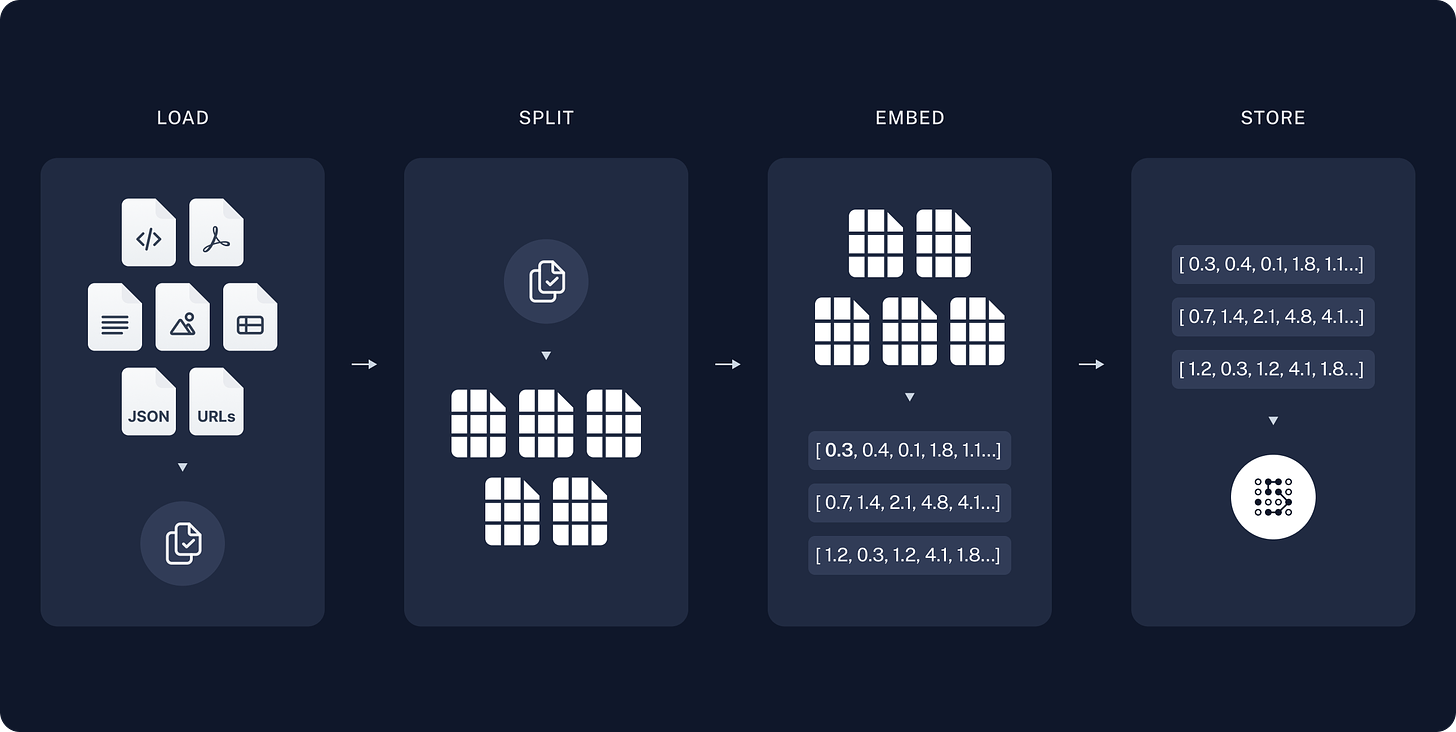
The data is loaded using document loaders, and then the text splitters break the large documents into manageable chunks for indexing and model input. Then storage and indexing are handled by the vectorstore and the embedding model for efficient retrieval.
Retrieval and Generation
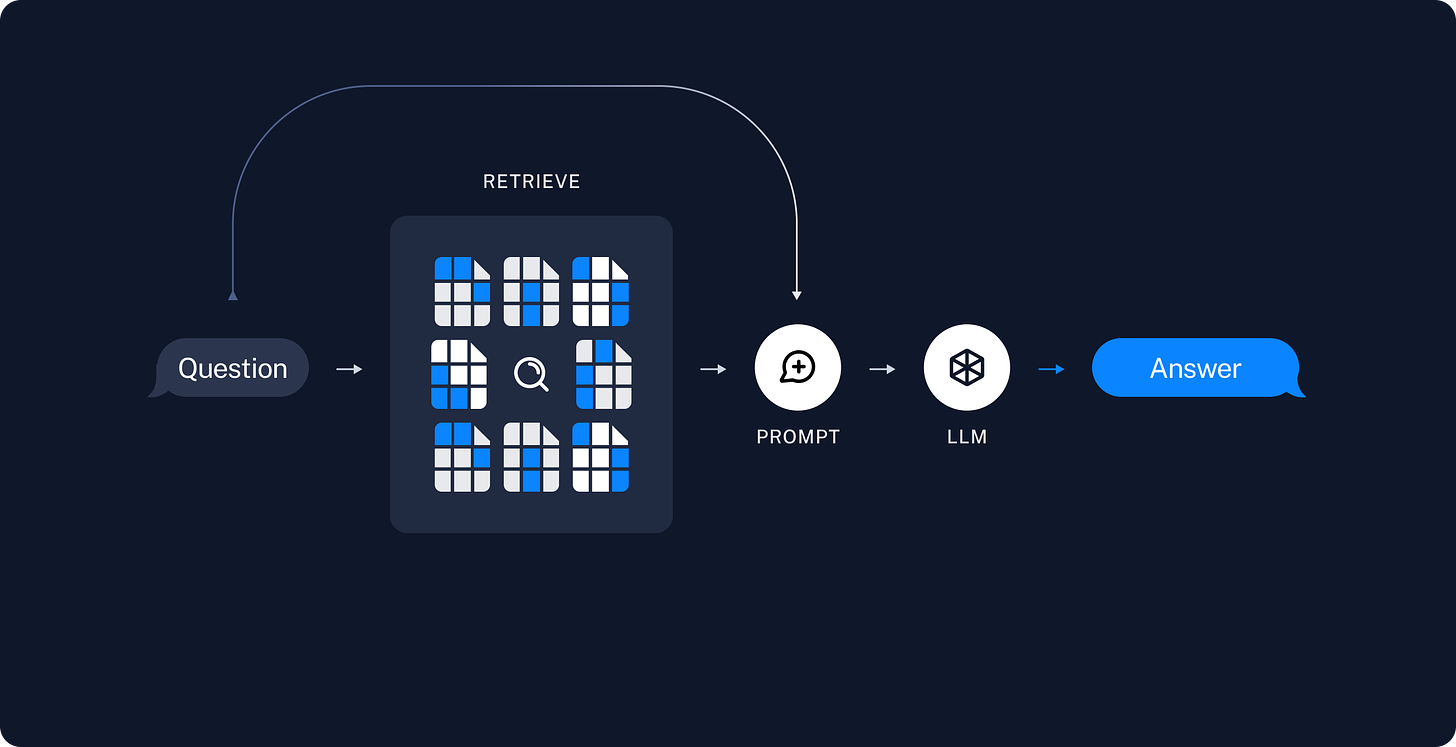
Then, for the retriever, given a user input, the relevant splits are retrieved from the storage using the retriever, and then the LLM produces an answer to the question that includes the question and the relevant data.
How do Large Language Models work Link to heading
Before going further, a neural network is a type of machine learning model that is inspired by the structure and function of the human brain. It consists of layers of interconnected nodes, or “neurons,” that process and transmit information. Each neuron receives input from other neurons or from the external environment, performs a computation on that input, and then sends the output to other neurons or to the output layer.
Today, most people have heard about LLMs like ChatGPT or even llama, but most people do not really know how they work. When ChatGPT came out sometime last November, it really shook the tech industry and the larger world.
So basically, the broken-down version of the explanation is that LLMs are trained on a huge chunk of data to predict the next word. Honestly speaking, no one fully understands the inner workings of LLMs, but researchers try daily to unravel more information. But don’t forget that unlike traditional programming that is done explicitly by programmers, LLMs like ChatGPT were built on neural networks that were trained using billions of words of ordinary language.
To understand how LLMs work, knowledge of vectors is needed. Language models represent them as a long list of numbers called vector space. Each word vector represents a point in an imaginary space, and then words similar in meaning are placed together. This representation also enables operations (numerical) on the words that could not be achieved by letters.
The idea of representing words vector-wise is good, but it doesn’t capture important facts about the language (context). Words can have different meanings in different sentences. For example, the word “bark” can refer to a dog’s sound and a tree’s covering.
LLMs like ChatGPT are able to represent the same word with different vectors depending on the context in which that word appears. There’s a vector for bark (dog sound) and bark (tree covering).
A typical LLM is organized into dozens of layers. Each layer takes in a sequence of vectors as input, a vector for each word, and adds information to clarify the meaning of that word and predict which word comes next. Each layer of an LLM is a transformer, which was first introduced by Google in their 2017 paper.
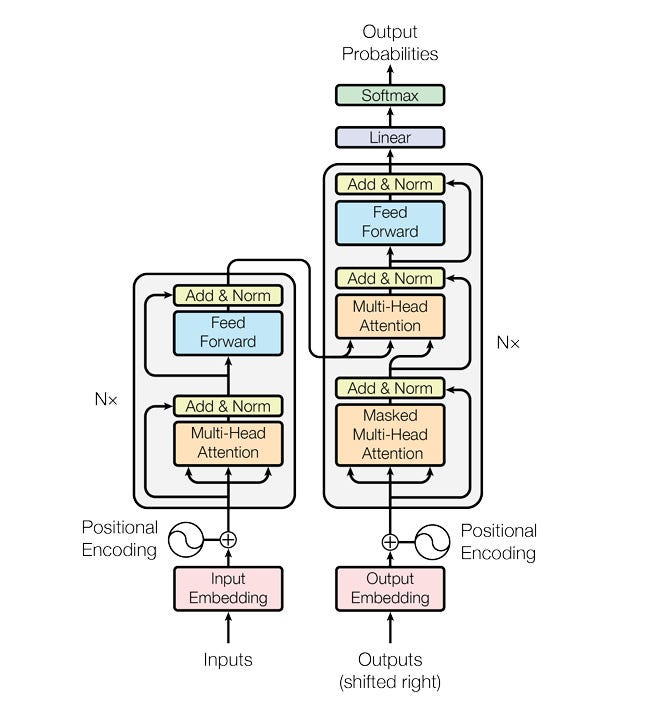
The layers of the transformer increasingly add context and meaning to the vector inputs that are being passed to them. The number of layers of the transformer varies depending on task complexity, dataset size, computational resources, and overfitting concerns. The most powerful version of GPT-3 has 96 layers. The final goal of the last layer of the LLM is to output a hidden state for the final word that includes all the information necessary to predict the next word.
The transformer architecture is based on the idea of self-attention, which allows the model to consider the entire input sequence when computing each output element rather than relying on a fixed-length context window or recurrence. This allows the model to effectively capture long-range dependencies in the input sequence.
The transformer architecture consists of an encoder and a decoder. The encoder takes in a sequence of tokens (e.g., words or characters) and outputs a sequence of vectors, called “keys,” “values,” and “queries.” The decoder then takes these vectors as input and generates an output sequence.
Encoder
The encoder consists of a stack of identical layers, each of which consists of a self-attention mechanism followed by a feed-forward neural network (FFNN). The self-attention mechanism allows the model to weigh the importance of each token in the input sequence based on its relevance to the current output. The FFNN processes the output of the self-attention mechanism and generates the final output for the layer.
Decoder
The decoder also consists of a stack of identical layers, each of which consists of a self-attention mechanism followed by an FFNN. However, the decoder also has an additional “attention” mechanism that allows it to consider the output of the encoder when generating each output element.
Self- Attention
The core innovation in transformers is the self-attention mechanism. Imagine you have a sentence, and you want the model to understand the relationships between different words. Self-attention allows each word in the sentence to focus on other words, assigning different levels of importance or attention.
For each word, three vectors are created: query (Q), key (K), and value (V). The attention score between a pair of words is calculated by taking the dot product of the query vector of one word and the key vector of the other. The scores are then scaled and passed through a SoftMax function to get the attention weights. Finally, the weighted sum of the value vectors gives the new representation for each word.
Mathematically,
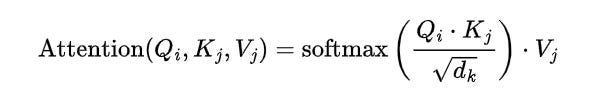
Multi-Head Attention
In order to enhance the model’s capability to capture different types of relationships, the self-attention mechanism is applied multiple times in parallel, each time with different learned linear projections for Q, K, and V. These parallel attention heads are then concatenated and linearly transformed to produce the final output.
Positional Encoding
Since transformers lack inherent information about the order of words in a sequence, positional encodings are added to the input embeddings. These encodings provide the model with information about the relative or absolute position of each token in the sequence.
Feed-Forward Network
After self-attention, the transformer architecture typically includes feedforward neural networks. Each position’s representation is fed through a fully connected layer with a non-linear activation function (commonly ReLU), providing the model with the ability to capture complex patterns and relationships.
Layer Normalization
Layer normalization is applied before the input is fed into each sub-layer (self-attention or feedforward). It is a technique used in neural networks to normalize the input of a layer across the feature dimension. It aims to address issues related to internal covariate shift, which is the change in the distribution of a layer’s inputs during training. It also helps stabilize and accelerate the training of deep neural networks.
Training
The model is trained using a labeled dataset and a suitable loss function, such as categorical cross-entropy for classification tasks or mean squared error for regression tasks. Training involves adjusting the model’s parameters using optimization algorithms like Adam, which use gradients computed through backpropagation.
Decoder Structure
The decoder in a transformer is responsible for generating the output sequence. It has a similar structure to the encoder but introduces a few additional components.
Masked Self-Attention
During training, the decoder can’t have access to future tokens in the target sequence to maintain causality. To achieve this, masked self-attention is employed in the decoder. The attention mechanism is applied only to the positions before the current position, ensuring that each position attends to its past positions and the input sequence.
Encoder-Decoder Attention
In addition to the masked self-attention, the decoder also utilizes an attention mechanism over the encoder’s output. This allows the decoder to focus on different parts of the input sequence while generating the output.
Positional Encoding (Decoder)
Similar to the encoder, the decoder incorporates positional encodings to provide information about the position of tokens in the output sequence.
Final Linear and SoftMax Layers
After the decoder’s self-attention and encoder-decoder attention mechanisms, the representations go through a feedforward neural network. The output of this network is then transformed using a linear layer, followed by a softmax activation function. This produces the probability distribution over the vocabulary for each position in the output sequence.
Training and Decoding
During training, the model is trained to minimize the difference between its predicted probabilities and the actual target distribution. During inference (decoding), the model generates the output sequence autoregressively, predicting one token at a time and using its own predictions to feed into the next step.
Beam Search
While decoding, beam search is often employed to explore multiple possible sequences simultaneously. Instead of greedily choosing the token with the highest probability at each step, beam search maintains a set of partially decoded sequences (beams) and expands the top-k candidates at each step.
Layer Normalization (Decoder)
Similar to the encoder, the decoder also uses layer normalization and residual connections to stabilize and ease the training process.
In summary, the final output of the transformer architecture is generated by the decoder, which takes the output of the encoder and generates a sequence of output tokens. The output tokens are generated using a SoftMax activation function, which computes a probability distribution over all possible tokens in the vocabulary. The token with the highest probability is then selected as the final output.
Thanks for reading. If you like posts like this, you can subscribe to my newsletter, nerd stack.